
Learning More from Accidents
2023-03-31
When accidents happen, there’s a seductive call to look for a root cause – that is, a chain of events without which, the accident would not have happened. In hindsight, root causes are apparently easy to identify; one works backwards from the accident, identifying causal threads until reaching the “root cause.” It’s simple, and it’s generally wrong.
In complex systems, root causes rarely exist. What exist are uncontrolled hazards, which are environmentally risky states, and triggers, which tip that risk into an unacceptable loss. Consider a manual configuration change in which a typographical error triggers an accident. It’s simple in hindsight to point at the human who made that change as being the root cause; and a set of proposed safeties might include “have a second set of eyes for every change” or “every person who makes a change has to watch for errors for one hour.” Both of those seem valuable at first glance, but are ultimately expensive with little benefit; neither acts to control the underlying hazards.
A hazard analysis for a system like this might start with identifying unacceptable losses like: “fail to serve users” or “send the wrong content to a user.” The hazards that might lead to a loss are more complex: “edge software doesn’t validate input is correct,” “inputs are not generated programmatically,” “inputs are not validated in a simulated environment,” and “correct server operations are not monitored for.” Stepping back further, one might find organizational hazards, like “developers don’t have clear priorities to build safety controls,” or “changes are not built from documented specifications.”
Why does this matter? In a sufficiently complex system, a single hazard is highly unlikely to result in a major accident. Usually, a significant number of hazards are triggered on the way to an accident. Selecting only one to “fix” will rarely stem the tide of accidents. Fixes that target only one root cause are often heavy-weight bandages, which slow the system down. A designed-safe system is a fast system – the true goal of safety is to enable high-performance operations (think about brakes as a system to enable speed)!
Enter STAMP. The Systems-Theoretic Accident Model and Processes, developed by Prof. Nancy Leveson at MIT, is a causal model of accidents in complex systems, which has two useful tools. CAST (Causal Analysis based on STamp) is a post-incident analysis model, which is heavily used by Akamai’s Safety Engineering Team when conducting incident reviews. STPA (Systems-Theoretic Process Analysis) is a hazard analysis model, useful in analyzing systems pre-accident.
STPA is a useful executive tool as well, even when reduced to its lightest incarnation. When looking at any system – software or organizational – ask three questions: What are the unacceptable losses? What hazards make those more likely? What control systems exist to mitigate those hazards?
If you struggle to answer those questions, one helpful mental model is the pre-mortem: Spend two minutes, and ask yourself, “If, in a year, this ended up failing, what was the bad outcome (unacceptable loss)? How did it happen (hazard)? What safeties should we have had (control systems)?”
Interested in reading more? Prof. Leveson’s CAST tutorial slides can be found at http://sunnyday.mit.edu/workshop2019/CAST-Tutorial2019.pdf, and the Partnership for a Systems Approach to Safety and Security is at https://psas.scripts.mit.edu/.
In complex systems, root causes rarely exist. What exist are uncontrolled hazards, which are environmentally risky states, and triggers, which tip that risk into an unacceptable loss. Consider a manual configuration change in which a typographical error triggers an accident. It’s simple in hindsight to point at the human who made that change as being the root cause; and a set of proposed safeties might include “have a second set of eyes for every change” or “every person who makes a change has to watch for errors for one hour.” Both of those seem valuable at first glance, but are ultimately expensive with little benefit; neither acts to control the underlying hazards.
A hazard analysis for a system like this might start with identifying unacceptable losses like: “fail to serve users” or “send the wrong content to a user.” The hazards that might lead to a loss are more complex: “edge software doesn’t validate input is correct,” “inputs are not generated programmatically,” “inputs are not validated in a simulated environment,” and “correct server operations are not monitored for.” Stepping back further, one might find organizational hazards, like “developers don’t have clear priorities to build safety controls,” or “changes are not built from documented specifications.”
Why does this matter? In a sufficiently complex system, a single hazard is highly unlikely to result in a major accident. Usually, a significant number of hazards are triggered on the way to an accident. Selecting only one to “fix” will rarely stem the tide of accidents. Fixes that target only one root cause are often heavy-weight bandages, which slow the system down. A designed-safe system is a fast system – the true goal of safety is to enable high-performance operations (think about brakes as a system to enable speed)!
Enter STAMP. The Systems-Theoretic Accident Model and Processes, developed by Prof. Nancy Leveson at MIT, is a causal model of accidents in complex systems, which has two useful tools. CAST (Causal Analysis based on STamp) is a post-incident analysis model, which is heavily used by Akamai’s Safety Engineering Team when conducting incident reviews. STPA (Systems-Theoretic Process Analysis) is a hazard analysis model, useful in analyzing systems pre-accident.
STPA is a useful executive tool as well, even when reduced to its lightest incarnation. When looking at any system – software or organizational – ask three questions: What are the unacceptable losses? What hazards make those more likely? What control systems exist to mitigate those hazards?
If you struggle to answer those questions, one helpful mental model is the pre-mortem: Spend two minutes, and ask yourself, “If, in a year, this ended up failing, what was the bad outcome (unacceptable loss)? How did it happen (hazard)? What safeties should we have had (control systems)?”
Interested in reading more? Prof. Leveson’s CAST tutorial slides can be found at http://sunnyday.mit.edu/workshop2019/CAST-Tutorial2019.pdf, and the Partnership for a Systems Approach to Safety and Security is at https://psas.scripts.mit.edu/.
Remote VideoConferencing Setup
2022-07-28
If you’ve heard me on a podcast, or seen me at a virtual conference, maybe you’ve been surprised at the audio and video capabilities I bring. Enough people have asked me to write them up, so here you go. I have four “modules” of my system, so I’ll talk about each of them separately.
Computers
While I have three computers on my desk, only two are really relevant for live production.
My primary desktop is an 8-core Mac Mini M1 with 16GB of RAM. I have an external Thunderbolt3 hub (IOGEAR GTD-733), which gives me both an extra ethernet port, as well as a DisplayPort. My primary monitor is an ASUS XG49V. My secondary monitor runs through an HDMI splitter, one of which goes to a teleprompter (see Desktop Video, below), the other to a confidence monitor (see Green Screen Video, below). The primary desktop, and the Desktop Video systems, are plugged into a UPS, which is, after an annoying power outage where it kept beeping while I was on a zoom, now set to mute.
My secondary desktop is mostly irrelevant to this, but since it’ll show up in pictures, for completeness: it’s also a Mac Mini M1, which I use for video production, and sometimes for writing. It has two monitors, one of which it shares with an XBox.
My third system is a laptop, an ancient and decrepit Macbook Air that even my kids don’t want to interact with. I use it for traveling (email and GDocs), and for presentations. It’ll appear below in Desktop Video.
Desktop audio
The core of my audio setup is a RODECaster Pro, which is a little overkill for my uses right now. It’s connected via USB-C to my primary desktop.
The RODECaster Pro has two microphones persistently connected. My primary mic is an ElectroVoice RE-320 on a [boom arm name]. I use that most of the time. The secondary mic is a Shure SM7B on a [boom arm, which I don’t recommend], which is a holdover from when my desktops were in different rooms and I could take calls anywhere. Nowadays, I use it for when I’m going to turn away from my monitor while on a call (the mic sits off to one side).
I also have a Belkin powered lightning-to-3.5mm adapter connected into the RODECaster, so I can leave my phone both powered up and connected. I can play sounds from my phone directly into computer-based audio/video calls, and I can use my audio setup to make phone-calls (or other app-based communications). This most often gets used to play music while waiting for a zoom meeting to start.
For audio output, I have a pair of BASN in-ear monitors that I wear (connected to the first output on the RODECaster, which is the only output that lets you independently control which audio inputs it listens to). I have a pair of studio monitors that sit on either side of my desk, which I use either to listen to music, or when I’m listening to an event that I’m not speaking in.
Additionally, not routed through the RODECaster Pro, I have a Jabra 410 speakerpuck. I usually use this if my wife and I are participating in an event together (if we’re not on separate systems).
Desktop Video
When I’m on a video call, I want high quality video. The heart of my video system is currently a Blackmagic ATEM Mini Extreme ISO (this is what enables the coolest feature, green screen plus picture-in-picture effects). The ATEM is connected via ethernet to the Mac Mini (main output), and it has eight HDMI inputs, plus an HDMI output which can show any of the inputs, or preview the next programmed change, or show a control panel with all of those, plus the actual video being sent to the Mac Mini. First I’ll list what is connected where, and then I’ll explain how I use the ATEM to control different scenes.
HDMI input one: the main camera. My main camera is a Canon EOS-RP, with a Canon 24-105 lens. Since the bookcase behind me is about 5 feet behind my head, I’ve got the aperture cranked all the way to f/14 so that both I and the books are in focus, but that means I need a lot of light. The camera is mounted on a PrompterPeople 15” teleprompter w/monitor, which itself is on a video tripod. For lighting, I have two keylights, one to either side of my desk; they are Neewer 660s. (Note: one is in a good spot, but the other has to be a little too close to me so it doesn’t reflect on the plaque behind me). This does put a bit of glare on me, so if I’m being recorded, I use a face primer (Elizabeth Mott’s Thank Me Later Mattifying) and powder (Revlon Colorstay pressed powder, 840 medium). When I get off camera, I use Neutrogena makeup remover towelettes.
HDMI input two: My over-the-shoulder camera. This is a Canon EOS Rebel T3 next to my secondary desktop. Mostly, that camera points at the main desktop setup so I can show it off.

HDMI input three: My laptop. The Macbook Air has a Belkin USB-C hub. This gives it power and ethernet, plus an HDMI port to connect to the ATEM. One USB port is used for an ergonomic mouse, and the other for a Logitech remote for advancing presentations. When I travel, I take this laptop, with a different USB-C hub and the presentation clicker.
HDMI input seven: This connects to the Green Screen Video setup.
HDMI input eight: Remember the HDMI splitter coming off my primary desktop? One of its outputs connects in here.
HDMI output: This goes right to the teleprompter monitor.
Primary use: Videoconferencing. The HDMI Output is set to Input 8, and the main output is set to Input 1.
Use: Showing Slides. If I want to show slides without sharing my screen, I can do one of to things: using the ATEM’s hard-coded picture-in-picture setup, make the slides on my laptop primary (input 2), and my face as in the inset (input 1); or I can use a programmed setting which has my face as the primary, and a custom picture-in-picture setup with the slides consuming a quarter of the screen. I only do this for simple, easy to read slides, or sometimes just putting up a picture.
Use: sharing my screen. If I want to share my screen, I’ll move the content I want to share up onto the secondary display (the teleprompter), and then switch the main output to Input 8. (If I do this when there is a Zoom window up there with self view on, there is a cool infinite mirrors effect).
Use: showing off my setup. With the Rebel plugged into input 2, I turn on the Rebel (it’ll auto-turn off in 30 minutes, long story about stupid tariff rules in Europe), I switch the main output to input 2.
Use: debugging my camera: I switch the HDMI output to input 1, and the teleprompter is now just the camera output.
Use: Green Screen video. With the Green Screen Video setup plugged into input 7, and specially formatted presentation on my laptop (input 3), I use two effects. I have a preloaded piece of media, which is a virtual stage. I turn on the Picture-in-picture effect, inserting input 3 overlaying the “screen” on the virtual stage. I turn on the Chroma Key effect in the ATEM, replacing the greenscreen of input 7 with the virtual stage. It’s a specially formatted layout because I don’t want to be standing in front of a slide deck, I want it off centered, like it’s behind me on a stage.
Green Screen Video
This is the area where I might have gone a little overboard. My office is similar to a suite in a hotel: there is a bedroom and a sitting room, but no doorway, just an arch. Everything I’ve described so far is in the sitting room. The green screen setup is mostly in the bedroom, with parts in the living room.
Everything that is attached to the walls uses Command strips, the velcro-style picture hanging kind. The adhesive on the poster strips is too weak.

Sound treatments
The walls are all covered in foam. The back wall uses an eggshell foam, with a green screen cloth stretched over it. The cloth is held in place with a set of quilt hangers. The remaining walls, and ceiling, have three-inch acoustic wedge foam, with some oddly shaped foam in other places. I also have acoustic foam mounted onto two tri-fold poster boards (like you’d use in a science fair). One of these shields the dresser I use for storing spare cables; the other blocks half of the archway.
The sitting room wall immediately behind my camera has six pictures, all of which are printed on acoustic foam.
Video setup
My camera is the Black Magic Pocket Cinema Camera (BMPCC) 6K. It’s mounted to a tripod on a rolling cage. The lens is a Canon CN-E 15.5-47. On a separate tripod, in front of the lens is an Ikan tablet teleprompter, so I can drop in an iPad if I’m giving a prepared talk. I have a dresser that is the storage location for most of my unused electronics and cables, on top of it sits a monitor (an LG 27” I picked up at Costco) which is the other output from the HDMI splitter which is my primary desktop’s secondary display output. I use this monitor mostly as a confidence monitor when giving talks.
Lighting is provided by four key lights. Two of them light up the green screen, and two light me up. They are Dracast S Series 500 (three from a package of S-plus, and one independently bought). The temperature on the back two are set to 4400K, and the front two to 5300K, which is also the temperature setting on the BMPCC.
The BMPCC HDMI output runs over to input 7 on the ATEM.
Audio setup
I use two microphones. On one channel is a RODE Boom microphone, that sits just off camera overhead of my usual standing position. The second channel is a Sennheiser wireless lavalier.For audio out, I connect a RODE Wireless Pro lavalier input to the monitor output on the RODECaster Pro, and connect a second set of BASN in-ear monitors to the Wireless Go output.
Use: Recorded video. For video I want to edit, I generally just record directly to the BMPCC, which has a USB-C portable hard drive, and I move the video over into DaVinci Resolve to edit. Alternatively, I can throw up Quicktime on my mac, and just record instead of (or, often, while) broadcasting live.
Use: Live video. See the Green Screen video use case at the bottom of the DesktopVideo section.
There you have it - a complete home video production studio.
Three Hidden Security Costs Behind Many Failed Projects
2021-12-01
As a long-time CISO, I’ve been on the receiving end of … a lot of vendor sales pitches. So much so that I created a quick template to respond to all of those unsolicited messages. For the most part, vendors would either quietly disappear, or reply with good grace (for many sales development representatives, even being acknowledged as having a difficult job was a positive improvement).
But sometimes, the responses would get a bit combative, usually with something like, “Don’t you care about your security? Don’t you know my solution will improve your security?” Let’s ignore that uncharitable first question, and focus on the second.
For any given vendor, are they likely to improve my security?
Yes, they will. Maybe by a small amount, maybe by giant leaps. Almost every vendor’s solution is going to make you more secure. The most challenging task a CISO faces isn’t spotting the handful of snake oil vendors (although that might be the most fun). It’s spotting the vendors who might make you a bit safer, but whose hidden costs are so massive that they’ll not only derail their own deployment, they’ll likely throw your entire security program off course.
Hidden Security Cost 1: Agents
A really large number of security products rely on the installation of an agent: a small bit of software that needs to be installed on every system to provide protections on that system. It sounds minor, trivial even, but it can be anything but.
If you have a completely homogenous environment – every system is identical to every other system – then agent integration is probably not a major issue.
Most environments, however, are more heterogeneous. Windows servers sit side-by-side with Linux servers (and the Linux servers come in a whole rainbow of different distributions), while applications are built in every environment known to humanity, and a few more we haven’t heard of … yet. An agent has to be able to safely operate in each and every one of those environments to provide full coverage; and if anything goes wrong during the deployment phase, your agent will be blamed, rightfully or not. And then disabled as part of the incident response, and you’ll have to start arguing after the incident to have it turned back on.
Agents also use resources on the machine. Ask your vendor for the performance overhead, and you’ll probably get a vague non-answer like, “oh, not very much, just a few percent.” A few percent of what, you might ask?
Often, agents are benchmarked on idle systems, and CPU usage might be measured. But what often matters is how the agent interacts with the system at peak load. Most enterprise users probably have a horror story about a laptop locking up for an antivirus scan right as they are headed into an important presentation; imagine the same concept happening to your webserver during a Black Friday sale.
Widespread agents are also a vector for supply chain attacks. The Solarwinds breach is one example, where an IT management agent, installed everywhere, created an avenue for compromise. The security risks of our own tools is a cost that most security teams don’t consider, but ought to be included in any evaluation.
Hidden Security Cost 2: Inscrutable Alerts
Anyone that has naively used a new security product that aims to find issues in their environment has encountered a flood of inscrutable alerts. Why does it matter that a machine replies to ICMP timestamp requests? (HINT: it really doesn’t).
The challenge with alert definitions in security products is that the incentives are entirely misaligned between the vendor and the buyer. The vendor doesn’t want to have the dreaded false negative – hiding an alert that is actually important – while the buyer is focused on the opposite problem – trying to avoid the meaningless alerts that don’t bring actionable value.
That actionable value in an alert is really hard to define in advance. Sometimes, it’s contextual. Perhaps an adversary can read all the files on a web server. Is that a problem? It might be; that server could have credentials to your production database. Or it might be much less interesting, if the server only handles a stock brochureware site.
For many security teams, they aren’t even the true consumer of the alerts. Alerts get passed on to the business unit, and the security team experiences the pain of being ignored. Often, that’s a reasonable reaction from a business team that gets handed a thousand actions items in one fell swoop. Many organizations end up in an uncomfortable situation where the devops team is demanding prioritization while the security team is demanding action. While both teams have a point, the valuable security work isn’t getting done.
At the heart of the problem is a mismatch between who the product is implicitly designed for – a deeply technical security architect and operator with excellent project management skills – and who actually ends up using it – a junior security analyst or project manager who is growing by leaps and bounds every day. The ability of a deep security professional to relatively quickly prioritize alerts would be handy, but that’s an expensive skill set to throw at thousands of alerts.
Unfortunately, most tools don’t have the architectural or organizational context to provide a first pass at prioritization to aid the analysts in quickly driving positive security change.
Hidden Security Cost 3: Complex Deployments and Organizational Friction
Whenever a complex project has to be rolled out to multiple organizations, no organization really wants to be first; because the first mover bears the burden of issues in integration. They likely also will need to redo the rollout, because the company will have learned lessons along the way about a better implementation than the one first proposed.
Most project managers have experienced this pain firsthand: peers wanting to see someone else’s success before they do the bare minimum, surprising roadblocks and speed bumps derailing a project that was already moving extremely slowly. And once a project has been moving too slowly for too long, it becomes implicitly deprioritized (“well, since we didn’t do it the last three years, why is it now important enough to do this year?”).
The organizational coordination cost increases supralinearly as a function of the technical cost: the more work a team will actually have to do, the more pain they’ll add in coordinating getting that work done. It’s not even vindictive or retaliatory; if an organization has too much work on its plate, it needs to push back on large or nebulously defined workloads.
Ending up as Shelfware
Many security products end up as shelfware, or partial implementations, because their rollouts fell afoul of one or more of these pitfalls.
And executives may not even realize that the projects have had limited or no success, because they’re still writing checks to the vendor for a solution that isn’t rolled out or is being ignored.
A version of this first appeared on the Orca Security CISO Corner.
But sometimes, the responses would get a bit combative, usually with something like, “Don’t you care about your security? Don’t you know my solution will improve your security?” Let’s ignore that uncharitable first question, and focus on the second.
For any given vendor, are they likely to improve my security?
Yes, they will. Maybe by a small amount, maybe by giant leaps. Almost every vendor’s solution is going to make you more secure. The most challenging task a CISO faces isn’t spotting the handful of snake oil vendors (although that might be the most fun). It’s spotting the vendors who might make you a bit safer, but whose hidden costs are so massive that they’ll not only derail their own deployment, they’ll likely throw your entire security program off course.
Hidden Security Cost 1: Agents
A really large number of security products rely on the installation of an agent: a small bit of software that needs to be installed on every system to provide protections on that system. It sounds minor, trivial even, but it can be anything but.
If you have a completely homogenous environment – every system is identical to every other system – then agent integration is probably not a major issue.
Most environments, however, are more heterogeneous. Windows servers sit side-by-side with Linux servers (and the Linux servers come in a whole rainbow of different distributions), while applications are built in every environment known to humanity, and a few more we haven’t heard of … yet. An agent has to be able to safely operate in each and every one of those environments to provide full coverage; and if anything goes wrong during the deployment phase, your agent will be blamed, rightfully or not. And then disabled as part of the incident response, and you’ll have to start arguing after the incident to have it turned back on.
Agents also use resources on the machine. Ask your vendor for the performance overhead, and you’ll probably get a vague non-answer like, “oh, not very much, just a few percent.” A few percent of what, you might ask?
Often, agents are benchmarked on idle systems, and CPU usage might be measured. But what often matters is how the agent interacts with the system at peak load. Most enterprise users probably have a horror story about a laptop locking up for an antivirus scan right as they are headed into an important presentation; imagine the same concept happening to your webserver during a Black Friday sale.
Widespread agents are also a vector for supply chain attacks. The Solarwinds breach is one example, where an IT management agent, installed everywhere, created an avenue for compromise. The security risks of our own tools is a cost that most security teams don’t consider, but ought to be included in any evaluation.
Hidden Security Cost 2: Inscrutable Alerts
Anyone that has naively used a new security product that aims to find issues in their environment has encountered a flood of inscrutable alerts. Why does it matter that a machine replies to ICMP timestamp requests? (HINT: it really doesn’t).
The challenge with alert definitions in security products is that the incentives are entirely misaligned between the vendor and the buyer. The vendor doesn’t want to have the dreaded false negative – hiding an alert that is actually important – while the buyer is focused on the opposite problem – trying to avoid the meaningless alerts that don’t bring actionable value.
That actionable value in an alert is really hard to define in advance. Sometimes, it’s contextual. Perhaps an adversary can read all the files on a web server. Is that a problem? It might be; that server could have credentials to your production database. Or it might be much less interesting, if the server only handles a stock brochureware site.
For many security teams, they aren’t even the true consumer of the alerts. Alerts get passed on to the business unit, and the security team experiences the pain of being ignored. Often, that’s a reasonable reaction from a business team that gets handed a thousand actions items in one fell swoop. Many organizations end up in an uncomfortable situation where the devops team is demanding prioritization while the security team is demanding action. While both teams have a point, the valuable security work isn’t getting done.
At the heart of the problem is a mismatch between who the product is implicitly designed for – a deeply technical security architect and operator with excellent project management skills – and who actually ends up using it – a junior security analyst or project manager who is growing by leaps and bounds every day. The ability of a deep security professional to relatively quickly prioritize alerts would be handy, but that’s an expensive skill set to throw at thousands of alerts.
Unfortunately, most tools don’t have the architectural or organizational context to provide a first pass at prioritization to aid the analysts in quickly driving positive security change.
Hidden Security Cost 3: Complex Deployments and Organizational Friction
Whenever a complex project has to be rolled out to multiple organizations, no organization really wants to be first; because the first mover bears the burden of issues in integration. They likely also will need to redo the rollout, because the company will have learned lessons along the way about a better implementation than the one first proposed.
Most project managers have experienced this pain firsthand: peers wanting to see someone else’s success before they do the bare minimum, surprising roadblocks and speed bumps derailing a project that was already moving extremely slowly. And once a project has been moving too slowly for too long, it becomes implicitly deprioritized (“well, since we didn’t do it the last three years, why is it now important enough to do this year?”).
The organizational coordination cost increases supralinearly as a function of the technical cost: the more work a team will actually have to do, the more pain they’ll add in coordinating getting that work done. It’s not even vindictive or retaliatory; if an organization has too much work on its plate, it needs to push back on large or nebulously defined workloads.
Ending up as Shelfware
Many security products end up as shelfware, or partial implementations, because their rollouts fell afoul of one or more of these pitfalls.
And executives may not even realize that the projects have had limited or no success, because they’re still writing checks to the vendor for a solution that isn’t rolled out or is being ignored.
A version of this first appeared on the Orca Security CISO Corner.
Four considerations for improving cloud security hygiene
2021-11-16
We think we understand what hygiene is, but what about cloud security hygiene? It’s not like our computers have teeth to brush. Although, if you have a child, you might be familiar with the challenges involved in even basic hygiene. Some of us might even have had conversations like this:
“Did you brush your teeth?”
“Yes!”
You smell in the vague vicinity of their mouth. “With toothpaste?”
“...”
Then you have to make sure they have brushed their back teeth. And the insides of their teeth, getting all the surfaces. And they flossed – deeply – between all of their teeth. And used mouthwash.
That’s not a bad model to start understanding security hygiene. There is some task you need to do regularly, and you need to do it everywhere. It’s not okay to just brush your teeth once a year, or only to brush the front teeth; you also can’t just patch software or check your security configurations once a year, or only for your most visible systems. And a vague check-in loves room for serious improvement.
Imagine a board member, asking a CEO, “Are all of your systems patched regularly?” We’re about to play a game of “Operator” as the CEO goes to find the answer, but instead of the words changing, the meaning of them changes. The board member probably really means “all of the company’s systems” and “patched within industry-standard windows based on criticality,” but that nuance will get lost. The CEO will turn to the CIO to ask the question, which implicitly reduces “all our systems” to “the systems the CIO is responsible for” and “patched regularly” becomes “patched within our internal maintenance windows.” The CIO asks their team, and so on. The metric reported back up ends up being something like “for our supported Windows servers, we apply the Microsoft patches within the planned maintenance windows 87% of the time.”
Those caveats get lost in the messaging back up to the CEO, so the company thinks it is doing just fine, when, in reality, only a small fraction of software is being tracked well. There’s a disincentive to provide better tracking, because that 87% number will go down when combined with another set of data with a lower score, and no one wants to explain why a metric just got worse.
Read the rest of this article on Dark Reading.
“Did you brush your teeth?”
“Yes!”
You smell in the vague vicinity of their mouth. “With toothpaste?”
“...”
Then you have to make sure they have brushed their back teeth. And the insides of their teeth, getting all the surfaces. And they flossed – deeply – between all of their teeth. And used mouthwash.
That’s not a bad model to start understanding security hygiene. There is some task you need to do regularly, and you need to do it everywhere. It’s not okay to just brush your teeth once a year, or only to brush the front teeth; you also can’t just patch software or check your security configurations once a year, or only for your most visible systems. And a vague check-in loves room for serious improvement.
Imagine a board member, asking a CEO, “Are all of your systems patched regularly?” We’re about to play a game of “Operator” as the CEO goes to find the answer, but instead of the words changing, the meaning of them changes. The board member probably really means “all of the company’s systems” and “patched within industry-standard windows based on criticality,” but that nuance will get lost. The CEO will turn to the CIO to ask the question, which implicitly reduces “all our systems” to “the systems the CIO is responsible for” and “patched regularly” becomes “patched within our internal maintenance windows.” The CIO asks their team, and so on. The metric reported back up ends up being something like “for our supported Windows servers, we apply the Microsoft patches within the planned maintenance windows 87% of the time.”
Those caveats get lost in the messaging back up to the CEO, so the company thinks it is doing just fine, when, in reality, only a small fraction of software is being tracked well. There’s a disincentive to provide better tracking, because that 87% number will go down when combined with another set of data with a lower score, and no one wants to explain why a metric just got worse.
Read the rest of this article on Dark Reading.
Food as Inclusion
2021-11-07
Every Friday night, Jews around the world welcome Shabbat around the dinner table. Saying blessings for each, we light candles, we drink wine, and we salt and eat bread.
Fire. Wine. Bread. Salt.
These aren’t just Jewish traditions; I just happen to think of them that way because that is the culture in which I experience them. But these are traditions that come in various forms in cultures all over the world, all through history. We welcome people into our midst by sharing food with them, and making them feel included and welcome in our spaces.
Food is sometimes a central part of work, too. We have lunch meetings. At offsite events, we usually eat food together. We need to recognize that how we engage with our colleagues around food is going to carry deep connotations for many of them around welcoming and inclusion.
There are many reasons that people might eat a different diet than you do. It might be religious or ethical; they have made a choice to not eat certain foods. It might be related to a disability; perhaps certain foods create physical discomfort, pain, or even mortal injury. It might even simply be related to healthy choices; perhaps certain foods interact with their metabolism in unhealthy ways.
If you’re a meal planner, the first step is in recognizing that feeding humans is a trust, and not merely a quick transaction. Most people with dietary restrictions are happy to tell you what foods they can and can’t eat. If you’re catering, you can just pass that list along (please don’t try to summarize it), and ask the caterer whether the main dishes can be adjusted, or whether a special plate would be needed. Share with the person how they get their meal from the caterer. Be open. Be communicative. Recognize that the person on the other end of this communication has likely been poisoned multiple times by otherwise well-meaning people, and don’t take offense if they want to see evidence that their restrictions are taken seriously.
Sometimes, though, the meal is the event. Perhaps you’re doing a team building exercise around a dinner table; if so, giving different food to someone at that table may be challenging to building trust and cohesiveness. Consider how a vegan might feel at a steakhouse, for instance! It’s one thing to have a different plate of food, but it might be something else entirely if the steakhouse is bringing around a plate of meats for everyone else to select from. Or maybe you’re planning a cooking class together. Having someone prepare food which they then can’t participate in? That’ll have the exact opposite effect, and destroy team cohesion.
If, for you, food is just an enjoyable activity, you’re probably not aware of how many people experience food restrictions, and you might be wandering into dangerous territory that harms more than it helps. Coming out of the "no contact with coworkers" world that CoViD has led us into, gatherings over food with colleagues are likely to start happening with increasing regularity. Take a few extra moments to thoughtfully approach food as an inclusive activity, because almost everyone appreciates being fed.
Fire. Wine. Bread. Salt.
These aren’t just Jewish traditions; I just happen to think of them that way because that is the culture in which I experience them. But these are traditions that come in various forms in cultures all over the world, all through history. We welcome people into our midst by sharing food with them, and making them feel included and welcome in our spaces.
Food is sometimes a central part of work, too. We have lunch meetings. At offsite events, we usually eat food together. We need to recognize that how we engage with our colleagues around food is going to carry deep connotations for many of them around welcoming and inclusion.
There are many reasons that people might eat a different diet than you do. It might be religious or ethical; they have made a choice to not eat certain foods. It might be related to a disability; perhaps certain foods create physical discomfort, pain, or even mortal injury. It might even simply be related to healthy choices; perhaps certain foods interact with their metabolism in unhealthy ways.
If you’re a meal planner, the first step is in recognizing that feeding humans is a trust, and not merely a quick transaction. Most people with dietary restrictions are happy to tell you what foods they can and can’t eat. If you’re catering, you can just pass that list along (please don’t try to summarize it), and ask the caterer whether the main dishes can be adjusted, or whether a special plate would be needed. Share with the person how they get their meal from the caterer. Be open. Be communicative. Recognize that the person on the other end of this communication has likely been poisoned multiple times by otherwise well-meaning people, and don’t take offense if they want to see evidence that their restrictions are taken seriously.
Sometimes, though, the meal is the event. Perhaps you’re doing a team building exercise around a dinner table; if so, giving different food to someone at that table may be challenging to building trust and cohesiveness. Consider how a vegan might feel at a steakhouse, for instance! It’s one thing to have a different plate of food, but it might be something else entirely if the steakhouse is bringing around a plate of meats for everyone else to select from. Or maybe you’re planning a cooking class together. Having someone prepare food which they then can’t participate in? That’ll have the exact opposite effect, and destroy team cohesion.
If, for you, food is just an enjoyable activity, you’re probably not aware of how many people experience food restrictions, and you might be wandering into dangerous territory that harms more than it helps. Coming out of the "no contact with coworkers" world that CoViD has led us into, gatherings over food with colleagues are likely to start happening with increasing regularity. Take a few extra moments to thoughtfully approach food as an inclusive activity, because almost everyone appreciates being fed.
The Fourth Dimension of Risk Management
2021-10-06
When security professionals talk about risk, especially with business executives, we often use metaphors rooted in the physical world. We might talk about coverage, and compare it to the length of a wall that surrounds a group of assets. Perhaps we talk about the height of the wall, to consider how comprehensive our defenses are. To make sure we’re focused on the right defenses, we think about the context of the asset behind the wall.
Three-dimensional analogies are helpful, but the most important dimension – time – is all too often left out of risk conversations. Consider the temporal continuity of risk: at some point in the future, something bad will happen. You don’t know when that will be, so you assign some probability to the risk. As time passes, that risk presumably increases, until it becomes certain, leaving the future for the present, and now you have an incident. After you correct the incident, hopefully you put in place a control to keep that specific risk from happening again, and the risk moves from the present into the past. Problem solved, right?
Not quite so fast, unfortunately. Controls instituted at incident tempo are often overly specific, and may miss out on underlying hazards. Let’s consider a wood fence. Wood decays over time, so one hazard could be written as “the fence parts will weaken and break over time.” One day, the fence section right next to the gate breaks. After corralling all of your horses, you reinforce that fence section, perhaps with some metal cross braces. While that specific incident is unlikely to happen again, every other fence section is still at risk from the uncontrolled hazard of decaying wood.
A good control framework doesn’t try to prevent a specific incident from recurring. Instead, it aims to identify an underlying hazard that appears in many risk scenarios, and puts in place controls to keep any of those scenarios from happening, allowing you to move entire categories of risk from the future straight into the past, skipping the unpleasantness of incidents hitting you in the present. In the wooden fence model, perhaps you monitor the strength of the wood, and institute a regular maintenance and replacement process to ensure that wood doesn’t have enough time to decay.
Security Risk Management then, has four different time horizons it works on: past, present, near-term, and future. Risk Management in the past is the domain of the Compliance team: ensuring that control frameworks that were established to manage a risk continue to do so. The present is the domain of the Security Operations or Incident Response teams: solving problems in real-time triggered by unmanaged risks. Future risk is, unfortunately, often not as clearly owned. Executive teams and boards are often focused on the near-term risks, seeking to identify the most predictable risks. This approach often extends the incident response model of “fix it as it breaks” to a just-in-time “fix it right before it breaks” risk reduction plan.
But future risk is actually where risk management processes can have the greatest impact, because a well-designed control structure can take whole swathes of risks and replace them with a strong control framework. It requires more discipline. Instead of fixing problems one at a time, an organization needs to remain focused on a mission, perhaps improving the state of vulnerability management or identity and access management (IAM).
Obviously, incident management needs to take as much of your time as it needs; that’s one of the definitions of incident, of course. There is a temptation to use the incident tempo of work to also address near-term risks. Unless you believe the risk is really about to happen (ask yourself, “Am I surprised it hasn’t happened yet?” as a way to test that belief), then you will need to identify the right blend of work across near-term and farther future risk. That may seem counterintuitive. Shouldn’t you prioritize near-term risk more than further out risk items?
The benefit of prioritizing further out risk items is you can more carefully create control structures that mitigate entire classes of risk, rather than focusing on the narrow slices that seem likely to happen in the next year. Consider IAM. There are a number of near-term risks around specific assets that too many users have access to; but the aggregate set of risks you can address with a robust IAM program is much greater – and it addresses risks that you might not otherwise prioritize, but which nonetheless will, at some point, cause you trouble.
A robust Security Operations function restores you in the present. A great Compliance function ensures your past remains safe. Thoughtful Risk Management can protect you from the future.
A version of this post originally appeared on the CISO Corner at Orca Security.
Three-dimensional analogies are helpful, but the most important dimension – time – is all too often left out of risk conversations. Consider the temporal continuity of risk: at some point in the future, something bad will happen. You don’t know when that will be, so you assign some probability to the risk. As time passes, that risk presumably increases, until it becomes certain, leaving the future for the present, and now you have an incident. After you correct the incident, hopefully you put in place a control to keep that specific risk from happening again, and the risk moves from the present into the past. Problem solved, right?
Controlling Risk
Not quite so fast, unfortunately. Controls instituted at incident tempo are often overly specific, and may miss out on underlying hazards. Let’s consider a wood fence. Wood decays over time, so one hazard could be written as “the fence parts will weaken and break over time.” One day, the fence section right next to the gate breaks. After corralling all of your horses, you reinforce that fence section, perhaps with some metal cross braces. While that specific incident is unlikely to happen again, every other fence section is still at risk from the uncontrolled hazard of decaying wood.
A good control framework doesn’t try to prevent a specific incident from recurring. Instead, it aims to identify an underlying hazard that appears in many risk scenarios, and puts in place controls to keep any of those scenarios from happening, allowing you to move entire categories of risk from the future straight into the past, skipping the unpleasantness of incidents hitting you in the present. In the wooden fence model, perhaps you monitor the strength of the wood, and institute a regular maintenance and replacement process to ensure that wood doesn’t have enough time to decay.
Risk Time Horizons
Security Risk Management then, has four different time horizons it works on: past, present, near-term, and future. Risk Management in the past is the domain of the Compliance team: ensuring that control frameworks that were established to manage a risk continue to do so. The present is the domain of the Security Operations or Incident Response teams: solving problems in real-time triggered by unmanaged risks. Future risk is, unfortunately, often not as clearly owned. Executive teams and boards are often focused on the near-term risks, seeking to identify the most predictable risks. This approach often extends the incident response model of “fix it as it breaks” to a just-in-time “fix it right before it breaks” risk reduction plan.
But future risk is actually where risk management processes can have the greatest impact, because a well-designed control structure can take whole swathes of risks and replace them with a strong control framework. It requires more discipline. Instead of fixing problems one at a time, an organization needs to remain focused on a mission, perhaps improving the state of vulnerability management or identity and access management (IAM).
Balancing Work
Obviously, incident management needs to take as much of your time as it needs; that’s one of the definitions of incident, of course. There is a temptation to use the incident tempo of work to also address near-term risks. Unless you believe the risk is really about to happen (ask yourself, “Am I surprised it hasn’t happened yet?” as a way to test that belief), then you will need to identify the right blend of work across near-term and farther future risk. That may seem counterintuitive. Shouldn’t you prioritize near-term risk more than further out risk items?
The benefit of prioritizing further out risk items is you can more carefully create control structures that mitigate entire classes of risk, rather than focusing on the narrow slices that seem likely to happen in the next year. Consider IAM. There are a number of near-term risks around specific assets that too many users have access to; but the aggregate set of risks you can address with a robust IAM program is much greater – and it addresses risks that you might not otherwise prioritize, but which nonetheless will, at some point, cause you trouble.
A robust Security Operations function restores you in the present. A great Compliance function ensures your past remains safe. Thoughtful Risk Management can protect you from the future.
A version of this post originally appeared on the CISO Corner at Orca Security.
You're behind
2021-09-11
“You’re behind.”
Legacies are complicated. Sometimes a catchphrase so oversimplifies an interaction that, in filling in the missing pieces, we create a false caricature, and do disservice to the person we would honor.
Danny Lewin was murdered a score of years ago today. He left behind a family, friends, colleagues, and the company he’d founded; a hole in the world that will never be filled. It will never be filled partly because Danny himself was always behind, always trying to fill the holes in the world he saw.
Each of those whose lives were touched by Danny knew a different piece of him, and we often try to capture the spark that ignited us. We found comfort in his own catchphrases, and we repeated them to each other, and to new colleagues, in an effort to continue to inspire ourselves, and others.
“You’re behind.”
It was one of Danny’s favorite catchphrases. Devoid of context, it sounds harsh. But when I heard it from him, it wasn’t. Because Danny would tackle impossible problems, and invent and implement solutions after he’d already committed himself. Launching Akamai fit that mold; Danny was going to change the world, even if he didn’t quite foresee how. Danny himself was behind, and you had, for whatever reason, elected to join him.
And now you’re both behind. There’s a sense of freedom in that moment. Nothing else matters except getting the job done, and it really is a team effort. I wrote a decade ago about the building of the world’s first secure content delivery network. It was Danny’s vision … but it was my design. Danny’s ego was big enough to accept that others could contribute, and it didn’t need to be done his way. When Danny told me that I was behind, it wasn’t a judgement on me. It was a judgement on the rest of the world, because no one else had even tried to tackle these problems yet. But we were in it together, and that was always clear.
“You’re behind.”
A decade later, new colleagues struggled with that message. It no longer sounded to them like a team message; the chaos of a startup had been replaced with the hierarchy of a successful enterprise. And sent across the vast gulf that sits between a senior executive and new employee, “You’re behind” sounded accusatory, a promise of retaliation for insufficient progress on impossible tasks.
In simplifying Danny’s legacy to that one phrase, it was easy for people to see him as a monster. A generation later, people didn’t see the fighter who stood by your side as you both tackled the impossible. Instead, they heard an unfeeling dictator who asked the impossible, and discarded anyone who disagreed with him.
Legacies are more complicated than a simple catchphrase can convey. As a leader, it’s important for us to remember that a quip carries, for us, years of history and shared knowledge. Stripped of that context, when we communicate with someone new, it will be processed based on the literal meaning of the words, flavored with whatever context the recipient brings to the table. Over time, as fewer and fewer people share the original context, we need to spend more energy building shared context to make the catchphrases remain relevant and helpful.
If we want to honor a legacy, it’s on us to embody the spirit that we want to convey. Otherwise, we become monsters to others whom we have failed to communicate with, who just hear the simple words we use. Telling to others the stories that we carry in our heart, so that messages carry the context we want. Listening to those around us, so that we recognize when our messages become harmful. Being a leader requires continuous and active improvement. As Danny might say:
“You’re behind.”
Legacies are complicated. Sometimes a catchphrase so oversimplifies an interaction that, in filling in the missing pieces, we create a false caricature, and do disservice to the person we would honor.
Danny Lewin was murdered a score of years ago today. He left behind a family, friends, colleagues, and the company he’d founded; a hole in the world that will never be filled. It will never be filled partly because Danny himself was always behind, always trying to fill the holes in the world he saw.
Each of those whose lives were touched by Danny knew a different piece of him, and we often try to capture the spark that ignited us. We found comfort in his own catchphrases, and we repeated them to each other, and to new colleagues, in an effort to continue to inspire ourselves, and others.
“You’re behind.”
It was one of Danny’s favorite catchphrases. Devoid of context, it sounds harsh. But when I heard it from him, it wasn’t. Because Danny would tackle impossible problems, and invent and implement solutions after he’d already committed himself. Launching Akamai fit that mold; Danny was going to change the world, even if he didn’t quite foresee how. Danny himself was behind, and you had, for whatever reason, elected to join him.
And now you’re both behind. There’s a sense of freedom in that moment. Nothing else matters except getting the job done, and it really is a team effort. I wrote a decade ago about the building of the world’s first secure content delivery network. It was Danny’s vision … but it was my design. Danny’s ego was big enough to accept that others could contribute, and it didn’t need to be done his way. When Danny told me that I was behind, it wasn’t a judgement on me. It was a judgement on the rest of the world, because no one else had even tried to tackle these problems yet. But we were in it together, and that was always clear.
“You’re behind.”
A decade later, new colleagues struggled with that message. It no longer sounded to them like a team message; the chaos of a startup had been replaced with the hierarchy of a successful enterprise. And sent across the vast gulf that sits between a senior executive and new employee, “You’re behind” sounded accusatory, a promise of retaliation for insufficient progress on impossible tasks.
In simplifying Danny’s legacy to that one phrase, it was easy for people to see him as a monster. A generation later, people didn’t see the fighter who stood by your side as you both tackled the impossible. Instead, they heard an unfeeling dictator who asked the impossible, and discarded anyone who disagreed with him.
Legacies are more complicated than a simple catchphrase can convey. As a leader, it’s important for us to remember that a quip carries, for us, years of history and shared knowledge. Stripped of that context, when we communicate with someone new, it will be processed based on the literal meaning of the words, flavored with whatever context the recipient brings to the table. Over time, as fewer and fewer people share the original context, we need to spend more energy building shared context to make the catchphrases remain relevant and helpful.
If we want to honor a legacy, it’s on us to embody the spirit that we want to convey. Otherwise, we become monsters to others whom we have failed to communicate with, who just hear the simple words we use. Telling to others the stories that we carry in our heart, so that messages carry the context we want. Listening to those around us, so that we recognize when our messages become harmful. Being a leader requires continuous and active improvement. As Danny might say:
“You’re behind.”
Risk at the Margin
2021-04-02
Humans are, generally, pretty awesome at risk management. Why, then, do we seem to be so bad at it – and in so many different ways – when it comes to assessing risk in the CoViD era?
Risk Models
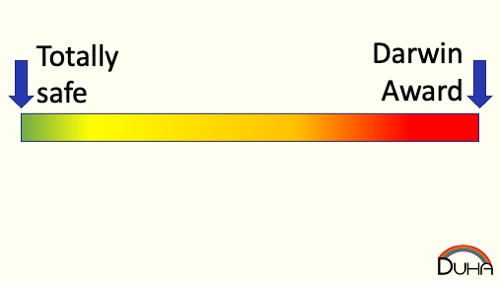
First, let’s talk about how humans make most risk decisions. Risk comes in a lot of different flavors (injury, long-term health, short-term health, embarrassment, financial, ….), and everyone weights those flavors differently. For simplicity, I’m going to talk about risk as if it lives on a single, linear scale, like so:
A human has an aggregate risk tolerance, somewhere on that scale:
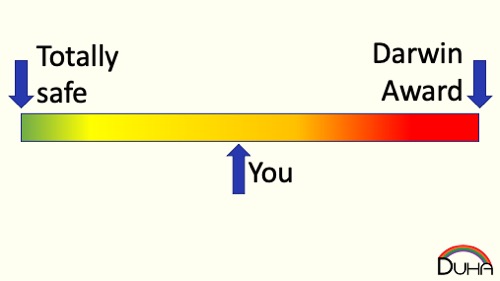
Really, you’re almost certainly all the way over on the left. Humans are really risk averse, because we think we’re sort of immortal, and we don’t want to jeopardize that.
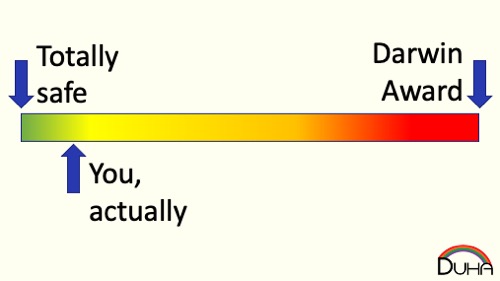
When you assess an activity, you’re quickly going to put it either to your left (Safe! Do this!) or your right (Unsafe! Don't do that!). While the “safe” activity might actually increase your risk, it seems like an activity you already accept, so you probably don’t consider it to, on the whole, make you less safe. For only a tiny amount of decisions do you need to actually think about the risk.
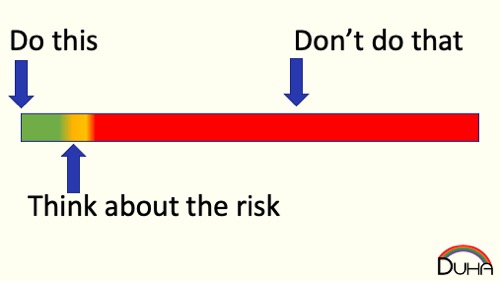
That area in between “safe” and “unsafe” is really small. Most of the time, you don’t ever have to evaluate a set of choices that sit on the margin between safe and unsafe, or be forced to pick between two unsafe activities. The distance between safe and unsafe is extremely small, although from our personal perspective, it seems massively large, since just about all risk decisions that we ever think about happen inside the margin.

This presents a hazard for us: we believe that the decision between "safe" and "unsafe" is really obvious, because the choices are so far apart, when, really, many of these choices are separated by a tiny amount, and even small errors in our decision-making process may put something on the "wrong" side.
Making decisions
Human decision-making can be modeled using Boyd's OODA Loop: we observe an input, we orient that input to our model of the world, we decide what we should do, and then we act on our plan.
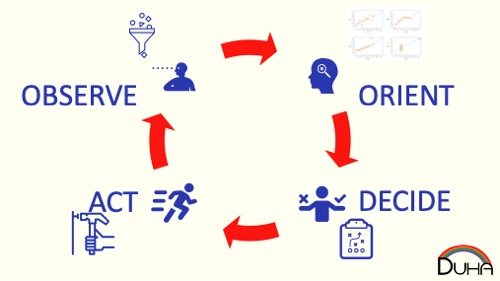
We do this so often, that our brains have optimized to perform our decision-making without thinking about it. We're like a machine-learning algorithm on steroids; our minds rapidly pattern match to get to a quick, cognitively-cheap, good enough solution, so you move from "Observe" to "Act" before you can even get introspective about your decision.
Orientation often starts with pulling models you think you know about, and using those as rough approximations. So CoViD might be “like the flu, but worse,” even though CoViD risk bears less resemblance to flu risk than cricket has to baseball. Sure, we can plan going to a cricket game by starting with the baseball rules and modifying them until we have cricket, but your sense of a three-hour game is woefully inaccurate.
One failure mode is that once you bucket a novel risk on one side of your margin or the other, you will not consider it further. “CoViD is just like the flu, so I’ll behave normally” and “CoViD is the end of the world, let’s enter a post-apocalyptic dystopia” might describe ways this failure mode might kick in. Once you've bucketed the risk, it becomes really hard to move from "unsafe" to "safe." Let's put some arbitrary numbers onto our risk scale. Perhaps the most risk you'll accept to keep something in the "safe" bucket is 0.09 risk units, and the lowest risk that puts something in the unsafe bucket is 0.11 risk units.
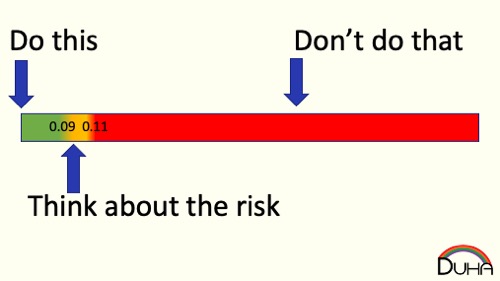
So it should seem like subtracting 0.02 risk units should let us change our decision. Unfortunately, we're really reluctant to change our minds about risk, and that partly because, once we think abut risk, we feel like we take a lot of risk - and our margins are much larger to us, perhaps ranging from 0.05 risk units all the way up to 0.95.

A different failure mode starts when you might correctly identify that the aggregate risk is in the margin, and requires complex thought (“I can stay home to avoid CoViD, but then I won’t make any money and I might go stir-crazy, so how do I safely engage”). You might miss steps that would be helpful: KN95 masks, fresh air, allow air diffusion before sharing a space, don’t sing in an enclosed area. You’ll need to mitigate: as your perception of risk goes up, you’ll take safety measures to push it down. (Note that as your perception of risk goes down, you’ll remove safety measures to let it come back up).

Using the flawed model of CoViD-as-flu-but-worse, you might convince yourself that certain mitigating steps will help more than they do: rigorous surface washing, eliminate shared objects, wear lightweight cloth masks everywhere. You think you've reduced the risk of your choices down into the safe zone, even if you haven't. (Or your risk was in your safe zone, but you were wrong about the risk, and the safety theater measures you engage in aren't changing your risk). On the other hand, you might use the inverse (and also flawed) model of CoViD-as-flu-but-better, and convince yourself that it's okay to take even more risks, because the people telling you it's dangerous are clearly wrong, so what else are they wrong about?
The Failure of Expertise
It's natural to want to ask for help. You ask an expert, “is this safe?” That’s a loaded question. Almost nothing is “safe”. While you really want to ask, “Given that I’m comfortable with this level of risk, what actions should I be taking?,” a risk expert hears “Tell me everything is okay,” and they aren’t going to do that.
Only you can make risk choices on your behalf, because only you can decide if the reward is worth the risk for you. An expert, who isn’t you, is generally going to err on the side of extreme caution, because they have an entirely different risk problem: If they say something is “safe,” and there is a bad outcome, it’s their fault and they get blamed. And since they’re often dealing across a population, even most “sort of safe” risks still pose a risk to someone in the population, so it’s easiest to have a very rigid canonical answer: Don’t do anything.
Experts in an area risk functionally end up only being able to veto things, because it’s too dangerous to do anything else. There is no incentive for an expert to ever suggest removing a safety control, even it is is high-cost and useless, because for them, the downside is too massive.
Confirmation Biases
If you make a “wrong” decision, it’s really hard to correct it, without radically new data. If you put a group of activities on the wrong side of your risk tolerance, revisiting it generally requires you to be able to challenge every risk choice you’ve ever made. That’s … not easy. Even somewhat new data is easier to discard if it challenges your decisions, or easy to rigorously hold onto if it supports them (even if it later turns out to be incorrect).
Inspecting your models is one of the most helpful things you can do, but it’s hard; especially if you’ve been arguing loudly against people who made different choices than you. You risk the embarrassment of agreeing with someone that you’ve said was foolish, so it’s simpler to dig in.
Risk at the Margin
That risk that lives in your margin you might have adjusted to push it just barely to one side or another (“I’ve mitigated risk enough that I choose to do this” vs. “I can’t mitigate this risk so I won’t do this activity”). However, you are likely now going to stop inspecting that risk; it’s either in the Safe or Unsafe buckets. Most people don’t waste cognitive capacity keeping track of marginal risk once they’ve bucketed it.
Boiling the Frog
If it’s hard to deal with a wrong risk choice, consider how much harder it is to deal with a mostly right risk choice, when the world changes and now that choice becomes wrong. As incremental evidence comes in, you’re going to keep your choice on whichever side of your risk tolerance you placed it, because that’s easier. But if you’d just barely moved it to one side, ignoring evidence that it is pushing to the other side is dangerous … but really easy.
Make your Predictions
One way to treat this risk confusion is to commit to predictions in advance. “When all the adults in my house are fully vaccinated, then they can go eat lunch at a restaurant.” That’s a safe commitment to make in advance, but harder to do in real time; but by depersonalizing a decision a little bit – you’re making the decision for your future self, so you’re a little more invested than an expert – you can engage conscious risk decision-making to your benefit.
Risk Models
First, let’s talk about how humans make most risk decisions. Risk comes in a lot of different flavors (injury, long-term health, short-term health, embarrassment, financial, ….), and everyone weights those flavors differently. For simplicity, I’m going to talk about risk as if it lives on a single, linear scale, like so:
A human has an aggregate risk tolerance, somewhere on that scale:
Really, you’re almost certainly all the way over on the left. Humans are really risk averse, because we think we’re sort of immortal, and we don’t want to jeopardize that.
When you assess an activity, you’re quickly going to put it either to your left (Safe! Do this!) or your right (Unsafe! Don't do that!). While the “safe” activity might actually increase your risk, it seems like an activity you already accept, so you probably don’t consider it to, on the whole, make you less safe. For only a tiny amount of decisions do you need to actually think about the risk.
That area in between “safe” and “unsafe” is really small. Most of the time, you don’t ever have to evaluate a set of choices that sit on the margin between safe and unsafe, or be forced to pick between two unsafe activities. The distance between safe and unsafe is extremely small, although from our personal perspective, it seems massively large, since just about all risk decisions that we ever think about happen inside the margin.
This presents a hazard for us: we believe that the decision between "safe" and "unsafe" is really obvious, because the choices are so far apart, when, really, many of these choices are separated by a tiny amount, and even small errors in our decision-making process may put something on the "wrong" side.
Making decisions
Human decision-making can be modeled using Boyd's OODA Loop: we observe an input, we orient that input to our model of the world, we decide what we should do, and then we act on our plan.
We do this so often, that our brains have optimized to perform our decision-making without thinking about it. We're like a machine-learning algorithm on steroids; our minds rapidly pattern match to get to a quick, cognitively-cheap, good enough solution, so you move from "Observe" to "Act" before you can even get introspective about your decision.
Orientation often starts with pulling models you think you know about, and using those as rough approximations. So CoViD might be “like the flu, but worse,” even though CoViD risk bears less resemblance to flu risk than cricket has to baseball. Sure, we can plan going to a cricket game by starting with the baseball rules and modifying them until we have cricket, but your sense of a three-hour game is woefully inaccurate.
One failure mode is that once you bucket a novel risk on one side of your margin or the other, you will not consider it further. “CoViD is just like the flu, so I’ll behave normally” and “CoViD is the end of the world, let’s enter a post-apocalyptic dystopia” might describe ways this failure mode might kick in. Once you've bucketed the risk, it becomes really hard to move from "unsafe" to "safe." Let's put some arbitrary numbers onto our risk scale. Perhaps the most risk you'll accept to keep something in the "safe" bucket is 0.09 risk units, and the lowest risk that puts something in the unsafe bucket is 0.11 risk units.
So it should seem like subtracting 0.02 risk units should let us change our decision. Unfortunately, we're really reluctant to change our minds about risk, and that partly because, once we think abut risk, we feel like we take a lot of risk - and our margins are much larger to us, perhaps ranging from 0.05 risk units all the way up to 0.95.
A different failure mode starts when you might correctly identify that the aggregate risk is in the margin, and requires complex thought (“I can stay home to avoid CoViD, but then I won’t make any money and I might go stir-crazy, so how do I safely engage”). You might miss steps that would be helpful: KN95 masks, fresh air, allow air diffusion before sharing a space, don’t sing in an enclosed area. You’ll need to mitigate: as your perception of risk goes up, you’ll take safety measures to push it down. (Note that as your perception of risk goes down, you’ll remove safety measures to let it come back up).
Using the flawed model of CoViD-as-flu-but-worse, you might convince yourself that certain mitigating steps will help more than they do: rigorous surface washing, eliminate shared objects, wear lightweight cloth masks everywhere. You think you've reduced the risk of your choices down into the safe zone, even if you haven't. (Or your risk was in your safe zone, but you were wrong about the risk, and the safety theater measures you engage in aren't changing your risk). On the other hand, you might use the inverse (and also flawed) model of CoViD-as-flu-but-better, and convince yourself that it's okay to take even more risks, because the people telling you it's dangerous are clearly wrong, so what else are they wrong about?
The Failure of Expertise
It's natural to want to ask for help. You ask an expert, “is this safe?” That’s a loaded question. Almost nothing is “safe”. While you really want to ask, “Given that I’m comfortable with this level of risk, what actions should I be taking?,” a risk expert hears “Tell me everything is okay,” and they aren’t going to do that.
Only you can make risk choices on your behalf, because only you can decide if the reward is worth the risk for you. An expert, who isn’t you, is generally going to err on the side of extreme caution, because they have an entirely different risk problem: If they say something is “safe,” and there is a bad outcome, it’s their fault and they get blamed. And since they’re often dealing across a population, even most “sort of safe” risks still pose a risk to someone in the population, so it’s easiest to have a very rigid canonical answer: Don’t do anything.
Experts in an area risk functionally end up only being able to veto things, because it’s too dangerous to do anything else. There is no incentive for an expert to ever suggest removing a safety control, even it is is high-cost and useless, because for them, the downside is too massive.
Confirmation Biases
If you make a “wrong” decision, it’s really hard to correct it, without radically new data. If you put a group of activities on the wrong side of your risk tolerance, revisiting it generally requires you to be able to challenge every risk choice you’ve ever made. That’s … not easy. Even somewhat new data is easier to discard if it challenges your decisions, or easy to rigorously hold onto if it supports them (even if it later turns out to be incorrect).
Inspecting your models is one of the most helpful things you can do, but it’s hard; especially if you’ve been arguing loudly against people who made different choices than you. You risk the embarrassment of agreeing with someone that you’ve said was foolish, so it’s simpler to dig in.
Risk at the Margin
That risk that lives in your margin you might have adjusted to push it just barely to one side or another (“I’ve mitigated risk enough that I choose to do this” vs. “I can’t mitigate this risk so I won’t do this activity”). However, you are likely now going to stop inspecting that risk; it’s either in the Safe or Unsafe buckets. Most people don’t waste cognitive capacity keeping track of marginal risk once they’ve bucketed it.
Boiling the Frog
If it’s hard to deal with a wrong risk choice, consider how much harder it is to deal with a mostly right risk choice, when the world changes and now that choice becomes wrong. As incremental evidence comes in, you’re going to keep your choice on whichever side of your risk tolerance you placed it, because that’s easier. But if you’d just barely moved it to one side, ignoring evidence that it is pushing to the other side is dangerous … but really easy.
Make your Predictions
One way to treat this risk confusion is to commit to predictions in advance. “When all the adults in my house are fully vaccinated, then they can go eat lunch at a restaurant.” That’s a safe commitment to make in advance, but harder to do in real time; but by depersonalizing a decision a little bit – you’re making the decision for your future self, so you’re a little more invested than an expert – you can engage conscious risk decision-making to your benefit.
Leading to Representation
2021-02-26
It’s a trope among managers and executives that making significant inroads on building a more representatively diverse workforce is almost impossible. Moving the needle by even a fraction of a percentage point in a normal year is considered a massive success worth celebrating.
That’s a cop-out. It’s not easy, but it isn’t impossible. And here’s my roadmap for doing so.
First the data, so you can see the success. I started doing detailed tracking way too late in my career, in the middle of 2017, when I realized that the information I wanted wasn’t accessible via our normal manager toolkits, and it was too much labor to pull through my HR business partner. I kept a spreadsheet (all good databases start as Excel!), and I recorded, for all of my staff, a few fields: Name, Pay Grade, Country, Startdate, Gender, and Race. For those last two fields, I used a very small number of buckets to more closely align with Akamai HR norms. The Gender summary includes Male, Female, and Non-Binary; trans staff were, for this summary, grouped with the gender they had publicly declared at that time. Note that all of the people who worked for me are individual humans that I know and care about, and I do them disservice with any bucketing strategy; but this summary is aligned with the metrics that Akamai tracked on an annual basis.
Every six months, I’d make a new version of the spreadsheet, with an updated snapshot of the organization. I’d then summarize the data, so that I could compare trends across time. I looked at non-white staff in the US population (“Minority”), Black/Hispanic staff in the US, female staff in the global population (“Women”), as well as non-binary staff globally. I looked at crosscuts by seniority; staff in pay grades at or above manager level (“Senior”) versus those below manager levels (“Junior”). Additionally, I tracked longevity, to look at those with less than one year of company tenure (“New”), one to five years (“Mid”), and those with more than five years (“Long”). I used company tenure rather than team tenure intentionally, because I want to look at career progression in the company. Given the small number of non-binary staff, I don't drill into them in the detailed views, which only explore women, minority, and Black/Hispanic populations.
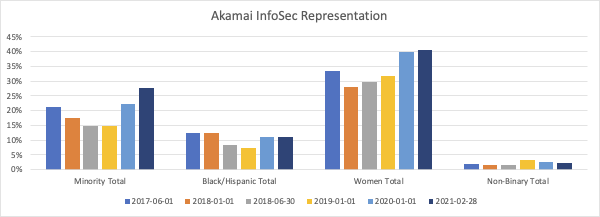
At first glance, you might wonder why the numbers went down in Minority and Women groups from the summer of 2017 to the following winter. That’s partially an artifact of temporary workers, and I learned to only really look at the data year to year to separate out our summer employees. In the last year, representation of women has leveled out, as well. I attribute that to a combination of factors, but it starts with retention: those twenty-one net new staff from the start of 2020 until now? That’s almost all hiring, because only one person left the team in that time period, and it was in the first week of 2020. Since an Akamai reduction in force early in 2018, my team has had only ten departures. If we’d had the tech industry average turnover, we’d’ve expected to lose fifty people over that three year window. We would have had to hire twice as many people over those three years to have maintained the same trajectory. There’s also just a bucketing artifact; the last five people to start in 2019 were women, and the first four in 2020 were men.
But that reduction in force, timed with a few other personnel issues on a small population, also significantly impacted the Black/Hispanic population. Because those issues are about specific individual humans, I won’t dive into them here, but there is a strong lesson in representation: when you have small numbers of a represented population, even a few changes at the same time are not only significant on a chart, but they are significant in effect, as your team becomes visibly less representatively diverse. You shouldn’t change your standards (unless they’re bad standards) to prevent this, but it’s another reason to drive for increased representation: so you aren’t tempted to ever just work to a metric. I don’t believe our team ever did, but I regret putting them in a position where they might have felt the pressure to just meet a metric.
Retention
Retention is a huge part of my strategy for changing representation. I’d actually argue that it is more important than hiring, because if you have a retention problem, then it’s going to affect your hiring as well. So how do you retain great staff?
Notice that I said “staff,” and not “women” or “minorities.” While your strategy to build an inclusive environment needs to be informed by the diverse needs of your team, if you try to build an environment that is only intended to be inclusive to one aspect of your team, you’re not going to succeed. Not for the obvious reason, either – sure, you’ll alienate your male staff – but for the less obvious. Your staff will notice your insincerity. You’re going to focus on being inclusive to stereotypes, rather than to the actual humans who work for you. There are a lot of aspects to inclusion, but I’m going to focus on three here: professional, work-life integration, and unique needs.
Professional inclusion is one of the most important things you can address. Every single member of your organization must have a professional development plan, not just the ones you see as “high potential.” You should identify their next two jobs (and there might be options), and make sure they and their manager are talking about the development they need to show, and what opportunities might be available for them. Your managers should remember those needs for when an opportunity does come up, so they are considering all of their staff, and not just the ones on their favorites list. For some of your staff, their next best opportunity may not be in your team. Help them to build the skills to leave, if that’s what is right for them – they might choose to stay instead, and you directly get the benefit. But indirectly, when everyone sees that more of your staff are being taken care of professionally, you benefit with increased engagement and retention.
Work-life integration is one of the simplest, but least well utilized retention strategies. If you don’t make it a focus, your managers will, unfortunately, betray you. But it’s not their fault: it’s yours. You believe that having an unlimited time off program is sufficient. But then you tell the team how many new priorities that they have to juggle, and you never let them deprioritize work. Your managers hear that as requiring more hours out of your employees. If you don’t make it very clear that you value the wellness of your staff, continuously and frequently, your managers will subvert your message. You need to make clear that you care more about the productivity of your employees over the next four years than over the next two weeks. You’ll actually end up with more productivity. Consider those 40 employees I didn’t lose. If we assume that it takes a year to hire and train someone to comparable productivity (I think that’s laughably short for most security jobs), my team has had almost twenty percent more productivity than a team with average turnover. That twenty percent buys an organization a lot of time flexibility, even ignoring the much higher productivity from staff with greater experience in the organization.
Years ago my team experimented with flexible work programs after parental leaves, allowing people to gradually phase in their work hours, rather than returning abruptly to a 5-day work week. Some staff didn’t need it, but others greatly valued it. We were in the process of officially codifying it when Akamai did us one better and added significantly more time to the parental leave program, but we still let staff phase themselves back into work.
Unique needs of your staff are a deep opportunity to excel. When only one person needs something, and it’s outside the usual set of requests, it really does matter. It’s easy to think you can just check a few boxes with having diverse interview panels and a better parental leave program, but your team will really pay attention when you notice, and react, to the unique needs of individuals. Maybe you have someone for whom the office lighting is a problem. Use your influence to push for a better solution for them. Perhaps you have a person who celebrates holidays that aren’t observed by most of the organization. Do you move your own meetings to accommodate one person? Do you make sure future meetings take those holidays into account? It’s the personal, small things that actually have the biggest impact in retention, because it creates a clear signal to everyone in your management team that your employees matter to you.
Longevity
Your goal shouldn’t just be about total representation in your organization, but needs to also look at representation among both your junior and senior staff. It’s tempting to try to tackle senior staff representation at once, and just go hire from outside. That presents a challenge, because senior staff hires are more complex in a number of ways. My observation of our team is that while about 45% of my team is senior, only around 25-30% of our new staff are. It ticks up a little for mid-tenure staff to 33%, and long-tenure staff are 70% senior. Looked at from the opposite direction, my 15 most senior staff – director level and up, 29% women, 18% US non-white, 11% US Black/Hispanic – are all long tenured personnel, with one exception, as the most recent team member approaches their fifth anniversary this summer. Clearly, my hiring strategy isn’t going to solve for senior staff quickly, but I can certainly check to see if we’re trending in the right direction.
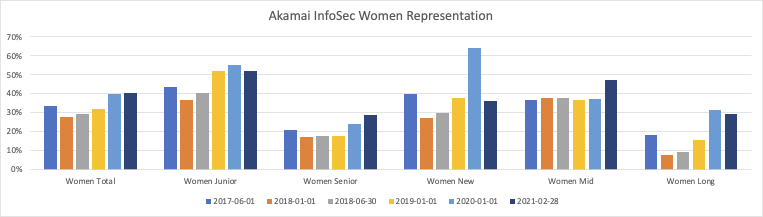
This chart is a little bit of an eye chart. The first cluster is just a copy of the overall representation for women from above. The next two clusters show the representation among junior staff and senior staff, and you can see that senior staff representation is finally starting to tick up over the last two years. Why? The final three charts have the story. While our hiring representation (as seen in the “New” cluster) has been relatively good, the retention is key. The mid-tenured staff is slowly growing more representative, and in the last two years we see long-tenured staff increasing in women’s representation. The long-tenure representation tracks pretty similarly to the senior representation, and that’s going to be key: ensuring that we have an internal pipeline of candidates for senior positions. Before I address that topic, a quick look at non-white US representation:
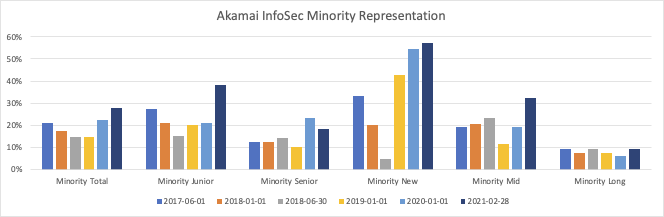
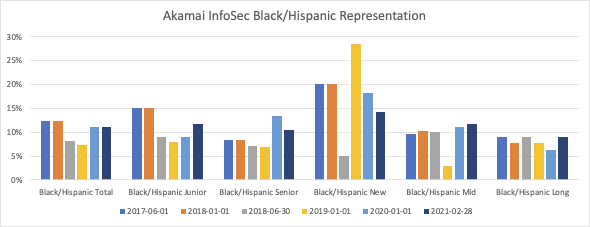
With lower numbers, and a little more jitter in the numbers, I see a pattern here that hints at even better futures. The upswing in minority representation in the new- and mid- tenures suggests that the long-tenure will start to rise in the next few years, which ought to really start driving the representation in the senior cohort. The smaller change in Black/Hispanic representation is more problematic, and, for the next CSO of Akamai, is clearly a place to investigate improvement efforts.
Promotions
The reason that retention matters so much in my philosophy is that the best senior staff are often those who come from within. Every time we have an opportunity to fill a senior staff role – either through the very rare departure, or through increased funding to support a business partner – we have the freedom to hire one person, or to promote a handful...and still hire one person. When an engineering team asks for a dedicated senior architect, that allows us to promote an architect, a senior security researcher, a security researcher II, and then hire a security researcher.
I also keep an eye on staff who haven’t had a promotion in a long time. When I meet with my staff for our annual strategic staffing check-in, they each bring their list of people that they think are due for a promotion. I also bring in my list, of the longest tenured people who haven’t seen a promotion in some time, so we can make sure we aren’t leaving people out, just because they aren’t making any noise.
But the real reason that promotions matter for representation numbers is because, frankly, the rest of the industry has done an atrocious job at developing competent senior staff, and the representation is awful. Great staff with experience, especially if they also happen to check a diversity box, are getting paid premiums beyond what I’m willing to pay, simply because a lot of employers are trying to quickly patch their representation problems. So if I want great senior staff, a lot of them are going to have to come from within. Additionally, it means that we have to spend less time with senior staff on culture and value basics, because they’ve all spent years creating the baseline we expect.
Hiring
Hiring new staff is where everyone thinks the heavy hitting happens. Like Moneyball, it’s not about home runs, it’s about just getting on base more often. I’m not expecting my recruiters to solve all of my representation issues, but I can make it easier for them, by setting reasonable expectations. We don’t hire unicorns. We’ll develop our staff, so they needn’t be perfect when they walk in the door. In fact, they may feel overwhelmed.
Insertion: Many of our positions aren’t classic cybersecurity jobs at all. The State of the Internet team (50% women, 25% minority) is a classic example. Half of the team started their careers as reporters. One is a data scientist. One is a still-recovering auditor. For many of our open positions, we go looking into adjacent career fields to find people with amazing skills that our career field is short on.
Early career: We make heavy use of a college internship program, and we focus our summer projects with one clear success criterion: Did the intern have a valuable summer experience? If we got useful work out of them, that’s icing on the cake, because our real goal is to find out if the intern will be a good fit for us, and if we’ll be a good fit for them. Our goal is to know, by the end of the summer, if we’re going to make an offer, and make it as soon as possible. We want the intern to know we want them back.
Transitions: Akamai runs a fantastic Technical Academy, in which we pay people to go through a six-month intense training program to help them convert/return to a tech job. Any time there is an ATA cohort where we have staff, we commit to hiring at least one person, because there is always at least someone who will be a good fit for a security team, even if they didn’t know it.
Market: We did occasionally hire in the cybersecurity job market. We paid careful attention to our job descriptions. Did they use language that might dissuade candidates? Did they contain voluminous requirements? You’ll need to check the job descriptions after you post them publicly, because sometimes, in an effort to standardize and comply with various labor rules, the job descriptions get edited after you submit them. We made sure to have visibly diverse hiring panels, as well, partly to help convince talented staff to join us, and partly as a sensor to detect candidates who might have a problem in a diverse environment.
The Long Road
There isn’t just one secret. You have to commit to a many-year effort to solve your representation issues. You have to lead with deliberate care, and be visible all through your management chain making your interest clear and visible, But you can make a difference, with effective intention.
That’s a cop-out. It’s not easy, but it isn’t impossible. And here’s my roadmap for doing so.
First the data, so you can see the success. I started doing detailed tracking way too late in my career, in the middle of 2017, when I realized that the information I wanted wasn’t accessible via our normal manager toolkits, and it was too much labor to pull through my HR business partner. I kept a spreadsheet (all good databases start as Excel!), and I recorded, for all of my staff, a few fields: Name, Pay Grade, Country, Startdate, Gender, and Race. For those last two fields, I used a very small number of buckets to more closely align with Akamai HR norms. The Gender summary includes Male, Female, and Non-Binary; trans staff were, for this summary, grouped with the gender they had publicly declared at that time. Note that all of the people who worked for me are individual humans that I know and care about, and I do them disservice with any bucketing strategy; but this summary is aligned with the metrics that Akamai tracked on an annual basis.
Every six months, I’d make a new version of the spreadsheet, with an updated snapshot of the organization. I’d then summarize the data, so that I could compare trends across time. I looked at non-white staff in the US population (“Minority”), Black/Hispanic staff in the US, female staff in the global population (“Women”), as well as non-binary staff globally. I looked at crosscuts by seniority; staff in pay grades at or above manager level (“Senior”) versus those below manager levels (“Junior”). Additionally, I tracked longevity, to look at those with less than one year of company tenure (“New”), one to five years (“Mid”), and those with more than five years (“Long”). I used company tenure rather than team tenure intentionally, because I want to look at career progression in the company. Given the small number of non-binary staff, I don't drill into them in the detailed views, which only explore women, minority, and Black/Hispanic populations.
At first glance, you might wonder why the numbers went down in Minority and Women groups from the summer of 2017 to the following winter. That’s partially an artifact of temporary workers, and I learned to only really look at the data year to year to separate out our summer employees. In the last year, representation of women has leveled out, as well. I attribute that to a combination of factors, but it starts with retention: those twenty-one net new staff from the start of 2020 until now? That’s almost all hiring, because only one person left the team in that time period, and it was in the first week of 2020. Since an Akamai reduction in force early in 2018, my team has had only ten departures. If we’d had the tech industry average turnover, we’d’ve expected to lose fifty people over that three year window. We would have had to hire twice as many people over those three years to have maintained the same trajectory. There’s also just a bucketing artifact; the last five people to start in 2019 were women, and the first four in 2020 were men.
But that reduction in force, timed with a few other personnel issues on a small population, also significantly impacted the Black/Hispanic population. Because those issues are about specific individual humans, I won’t dive into them here, but there is a strong lesson in representation: when you have small numbers of a represented population, even a few changes at the same time are not only significant on a chart, but they are significant in effect, as your team becomes visibly less representatively diverse. You shouldn’t change your standards (unless they’re bad standards) to prevent this, but it’s another reason to drive for increased representation: so you aren’t tempted to ever just work to a metric. I don’t believe our team ever did, but I regret putting them in a position where they might have felt the pressure to just meet a metric.
Retention
Retention is a huge part of my strategy for changing representation. I’d actually argue that it is more important than hiring, because if you have a retention problem, then it’s going to affect your hiring as well. So how do you retain great staff?
Notice that I said “staff,” and not “women” or “minorities.” While your strategy to build an inclusive environment needs to be informed by the diverse needs of your team, if you try to build an environment that is only intended to be inclusive to one aspect of your team, you’re not going to succeed. Not for the obvious reason, either – sure, you’ll alienate your male staff – but for the less obvious. Your staff will notice your insincerity. You’re going to focus on being inclusive to stereotypes, rather than to the actual humans who work for you. There are a lot of aspects to inclusion, but I’m going to focus on three here: professional, work-life integration, and unique needs.
Professional inclusion is one of the most important things you can address. Every single member of your organization must have a professional development plan, not just the ones you see as “high potential.” You should identify their next two jobs (and there might be options), and make sure they and their manager are talking about the development they need to show, and what opportunities might be available for them. Your managers should remember those needs for when an opportunity does come up, so they are considering all of their staff, and not just the ones on their favorites list. For some of your staff, their next best opportunity may not be in your team. Help them to build the skills to leave, if that’s what is right for them – they might choose to stay instead, and you directly get the benefit. But indirectly, when everyone sees that more of your staff are being taken care of professionally, you benefit with increased engagement and retention.
Work-life integration is one of the simplest, but least well utilized retention strategies. If you don’t make it a focus, your managers will, unfortunately, betray you. But it’s not their fault: it’s yours. You believe that having an unlimited time off program is sufficient. But then you tell the team how many new priorities that they have to juggle, and you never let them deprioritize work. Your managers hear that as requiring more hours out of your employees. If you don’t make it very clear that you value the wellness of your staff, continuously and frequently, your managers will subvert your message. You need to make clear that you care more about the productivity of your employees over the next four years than over the next two weeks. You’ll actually end up with more productivity. Consider those 40 employees I didn’t lose. If we assume that it takes a year to hire and train someone to comparable productivity (I think that’s laughably short for most security jobs), my team has had almost twenty percent more productivity than a team with average turnover. That twenty percent buys an organization a lot of time flexibility, even ignoring the much higher productivity from staff with greater experience in the organization.
Years ago my team experimented with flexible work programs after parental leaves, allowing people to gradually phase in their work hours, rather than returning abruptly to a 5-day work week. Some staff didn’t need it, but others greatly valued it. We were in the process of officially codifying it when Akamai did us one better and added significantly more time to the parental leave program, but we still let staff phase themselves back into work.
Unique needs of your staff are a deep opportunity to excel. When only one person needs something, and it’s outside the usual set of requests, it really does matter. It’s easy to think you can just check a few boxes with having diverse interview panels and a better parental leave program, but your team will really pay attention when you notice, and react, to the unique needs of individuals. Maybe you have someone for whom the office lighting is a problem. Use your influence to push for a better solution for them. Perhaps you have a person who celebrates holidays that aren’t observed by most of the organization. Do you move your own meetings to accommodate one person? Do you make sure future meetings take those holidays into account? It’s the personal, small things that actually have the biggest impact in retention, because it creates a clear signal to everyone in your management team that your employees matter to you.
Longevity
Your goal shouldn’t just be about total representation in your organization, but needs to also look at representation among both your junior and senior staff. It’s tempting to try to tackle senior staff representation at once, and just go hire from outside. That presents a challenge, because senior staff hires are more complex in a number of ways. My observation of our team is that while about 45% of my team is senior, only around 25-30% of our new staff are. It ticks up a little for mid-tenure staff to 33%, and long-tenure staff are 70% senior. Looked at from the opposite direction, my 15 most senior staff – director level and up, 29% women, 18% US non-white, 11% US Black/Hispanic – are all long tenured personnel, with one exception, as the most recent team member approaches their fifth anniversary this summer. Clearly, my hiring strategy isn’t going to solve for senior staff quickly, but I can certainly check to see if we’re trending in the right direction.
This chart is a little bit of an eye chart. The first cluster is just a copy of the overall representation for women from above. The next two clusters show the representation among junior staff and senior staff, and you can see that senior staff representation is finally starting to tick up over the last two years. Why? The final three charts have the story. While our hiring representation (as seen in the “New” cluster) has been relatively good, the retention is key. The mid-tenured staff is slowly growing more representative, and in the last two years we see long-tenured staff increasing in women’s representation. The long-tenure representation tracks pretty similarly to the senior representation, and that’s going to be key: ensuring that we have an internal pipeline of candidates for senior positions. Before I address that topic, a quick look at non-white US representation:
With lower numbers, and a little more jitter in the numbers, I see a pattern here that hints at even better futures. The upswing in minority representation in the new- and mid- tenures suggests that the long-tenure will start to rise in the next few years, which ought to really start driving the representation in the senior cohort. The smaller change in Black/Hispanic representation is more problematic, and, for the next CSO of Akamai, is clearly a place to investigate improvement efforts.
Promotions
The reason that retention matters so much in my philosophy is that the best senior staff are often those who come from within. Every time we have an opportunity to fill a senior staff role – either through the very rare departure, or through increased funding to support a business partner – we have the freedom to hire one person, or to promote a handful...and still hire one person. When an engineering team asks for a dedicated senior architect, that allows us to promote an architect, a senior security researcher, a security researcher II, and then hire a security researcher.
I also keep an eye on staff who haven’t had a promotion in a long time. When I meet with my staff for our annual strategic staffing check-in, they each bring their list of people that they think are due for a promotion. I also bring in my list, of the longest tenured people who haven’t seen a promotion in some time, so we can make sure we aren’t leaving people out, just because they aren’t making any noise.
But the real reason that promotions matter for representation numbers is because, frankly, the rest of the industry has done an atrocious job at developing competent senior staff, and the representation is awful. Great staff with experience, especially if they also happen to check a diversity box, are getting paid premiums beyond what I’m willing to pay, simply because a lot of employers are trying to quickly patch their representation problems. So if I want great senior staff, a lot of them are going to have to come from within. Additionally, it means that we have to spend less time with senior staff on culture and value basics, because they’ve all spent years creating the baseline we expect.
Hiring
Hiring new staff is where everyone thinks the heavy hitting happens. Like Moneyball, it’s not about home runs, it’s about just getting on base more often. I’m not expecting my recruiters to solve all of my representation issues, but I can make it easier for them, by setting reasonable expectations. We don’t hire unicorns. We’ll develop our staff, so they needn’t be perfect when they walk in the door. In fact, they may feel overwhelmed.
Insertion: Many of our positions aren’t classic cybersecurity jobs at all. The State of the Internet team (50% women, 25% minority) is a classic example. Half of the team started their careers as reporters. One is a data scientist. One is a still-recovering auditor. For many of our open positions, we go looking into adjacent career fields to find people with amazing skills that our career field is short on.
Early career: We make heavy use of a college internship program, and we focus our summer projects with one clear success criterion: Did the intern have a valuable summer experience? If we got useful work out of them, that’s icing on the cake, because our real goal is to find out if the intern will be a good fit for us, and if we’ll be a good fit for them. Our goal is to know, by the end of the summer, if we’re going to make an offer, and make it as soon as possible. We want the intern to know we want them back.
Transitions: Akamai runs a fantastic Technical Academy, in which we pay people to go through a six-month intense training program to help them convert/return to a tech job. Any time there is an ATA cohort where we have staff, we commit to hiring at least one person, because there is always at least someone who will be a good fit for a security team, even if they didn’t know it.
Market: We did occasionally hire in the cybersecurity job market. We paid careful attention to our job descriptions. Did they use language that might dissuade candidates? Did they contain voluminous requirements? You’ll need to check the job descriptions after you post them publicly, because sometimes, in an effort to standardize and comply with various labor rules, the job descriptions get edited after you submit them. We made sure to have visibly diverse hiring panels, as well, partly to help convince talented staff to join us, and partly as a sensor to detect candidates who might have a problem in a diverse environment.
The Long Road
There isn’t just one secret. You have to commit to a many-year effort to solve your representation issues. You have to lead with deliberate care, and be visible all through your management chain making your interest clear and visible, But you can make a difference, with effective intention.
Understanding Risk
2021-02-23
Operating or overseeing a business – whether it’s as a director, executive, or manager – requires an understanding of risk, and especially how it impacts your strategy. But risk is a nebulous concept. It means something different to everyone, so it helps to levelset not just on a working definition of risk, but on approaches to thinking both about novel risks (those that aren’t yet on your radar) and known risks (those that are on your radar).
What is Risk?
Risk is anything that has a chance of adversely impacting your business. Risk isn’t intrinsically a bad thing, all entities have a risk appetite that balances the risks they take against the rewards they seek. Companies have to invite risk to pursue rewards; consider that merely making a profit invites competitors who will increase your risk. Risks exist in many broad categories – often, a practitioner in one category thinks of their kind of risk as being the only kind that matters – and it’s important to apply risk management thoughts across the spectrum of risk. The most prevalent risk just comes from liquidity (having enough cash to operate), which can include credit risk (the money you are owed … doesn’t materialize). You might have risk that comes from your market (you need specific truths to operate, like a bear market or zero interest rates), your business strategy (your specific market strategy hinges on an underlying axiom, like people renting movies in a store), or compliance regimes (you can be put out of business simply for not following a rule). You can also face risks from reputation (if people no longer are willing to do business with you) or operations (your security and safety practices).
Within those broad risk areas, we can think of significant amounts of risk as coming from hazards. Hazards are the subset of risks that aren’t intrinsic to your strategy, and have the potential to be surprisingly disruptive.
Hazards come in many flavors. Some are procedural: in execution of your strategy, you might make errors. Some are adversarial or environmental: other entities outside your control could harm you through this hazard. And some are perverse incentives: you might incentive individuals on your team to do very dangerous things in execution of your strategy. Each of these requires different forms of oversight to address, especially in places where they might interact.
Procedural Hazards
Many control regimes – from Sarbanes-Oxley to the NIST CSF to a whole host of ISO frameworks – are designed to help companies manage process risk. Unfortunately, these frameworks, alone, seem to be insufficient to control those risks. Overseeing risk can be challenging, as hundreds of detailed controls across an entire enterprise are potentially relevant, and identifying specific problematic areas isn’t an easy task. Two important questions might help drive towards identifying hazards.
What is the scope of a control system? Perhaps a company has a strong control in Identity and Access Management, and can report flawless execution in ensuring that only appropriate staff get access to systems. But lost in the nuance of reporting is that the relevant control only applies to a subset of the systems in the company. It’s the most important set of systems, of course, but importance is in the perception of management. Right next to those important systems might be other, uncontrolled systems that don’t have good controls, which create hazards for the adjacent controlled systems. Understanding where controls don’t cover the full scope of a company is an important first step.
How effective is the control system? Some control systems look shiny from the outside, but on the inside, don’t actually provide meaningful protections. It’s important to understand if there is a simple measurement that summarizes the control, which is also tied into the protections the control provides. Perhaps the measure is reporting on activity (“We approved 75 products for launch this quarter”) and not on impact (“100% of products had absolutely no reported issues”). An impact measure might reveal implausibility, a failure rate of 0% is not necessarily an indicator of a strong system. It’s more likely an indicator of a control system that has no effect.
Combine these two questions as you consider how to report on the effectiveness of an overall control system. Control effectiveness should report both on scope (what percentage of the system is controlled?) and effectiveness (what is the measure of process effectiveness?). Risk appetite should be used to establish reasonable ranges for both of these measures, to identify when escalation will be needed to course correct, and how much escalation (telling executive management is likely a different threshold than telling the board). Identifying those thresholds before you cross them will save a lot of energetic conversation about whether or not something should be escalated.
Environmental and Adversarial Hazards
Some systems have defects that can go badly wrong if exploited in just the wrong way. Sometimes that exploit needs a malicious actor, a criminal who wants to create harm for your business. Other times that exploit doesn’t require malice; perhaps an extreme winter storm pushes your system outside its design limits.
These hazards are sometimes challenging to talk about. The hazards aren’t always easy to find, and rarely with a simple checklist. Sometimes the hazards are tolerable, you aren’t necessarily happy to have them, but you’ll tolerate them for a time. Sometimes, these hazards are so intertwined into your system design and business process that even if you do decide to reduce the hazard, you’ll need to spend years coordinating cross-functional projects to root it out.
Discovery: One way that many companies identify these hazards is to employ experts who just know where to look. Unfortunately, this approach relies on having a specific kind of unicorn: a deeply technical employee with broad-based knowledge of your entire system, a long memory to track issues, and the communication skills to educate your executive team about the hazards. A more reliable approach is to embed hazard analysis all throughout the design process, and capture the hazards into a registry; and have that registry continuously reviewed – perhaps reassessing a few a month – to keep it updated with known hazards.
Mitigation: Some of those hazards you will need to mitigate. You don’t need to reduce them all to zero (sometimes just taking the edge off by a little bit is sufficient to bring the risk back into your appetite), but once you decide to reduce the impact of the hazard, it’s helpful to identify success criteria. Think of success criteria as a contract with your future self: “if I do this much work, measurable by this outcome, and the world hasn’t changed to make this more dangerous, then I get to celebrate success.” It will be tempting along the way to move the goalposts closer, because mitigation projects can take longer than you originally expected. Inspect that urge. Did you really misestimate the danger originally, or do you just have fatigue and would like to be done, even if the hazard remains uncontrolled?
Awareness: Some of your hazards you aren’t going to mitigate. Perhaps the hazard is too embedded in your way of doing business. Maybe the hazard is just below the level where it would be urgent to fix. This is uncomfortable, because you’ll have to acknowledge the presence of these hazards, and it’s a natural reaction to avoid talking about them. But you must, because the only real way to understand the risk appetite is to actually talk about the hazards that you accept, especially in the context of all of the hazards contained in your registry. Gaining awareness (likely not comfort, but at least awareness) of which risks are accepted make assessing new and novel risks into an easier task.
Incentivized Hazards
The most pernicious hazards an organization faces are those that it creates for itself, by putting its own employees’ incentives at odds with its long-term best outcomes. Sometimes this might be through ill-thought through systemic incentives (consider JPMC’s “London whale” or the Wells Fargo cross-selling debacle); other times it might be created by specific pressures to achieve results (look at Volkswagen’s DieselGate or Theranos).
Most incentivized hazards create a tension between what ought to be the values and cultures of a company (which are often just plaques on a wall, rather than living touchstones), and the short-term needs of a company. Incentives can be novel solutions to a changing business environment, or might arise from impossible business needs. But detecting perverse incentives isn’t impossible; it just requires extra care.
Culture: We shouldn’t expect that employees will be the only line of defense against a hazard, but we should expect that they should feel uncomfortable with conflicting goals – but that they should feel comfortable raising that conflict with management. Organizational values should be viewed like a detour sign: they indicate which paths to avoid. Perhaps, to avoid a Wells Fargo style incident, a value like “Serve the best interests of our customers” would be helpful to create tension against “cross-sell as many products as possible to our existing customers.”
Changing business environment: When the environment alters in a significant fashion, novel solutions to the problem create an automatic perverse incentive: the novel solution absolutely cannot be permitted to fail. The team responsible for the solution is automatically incentivized to hide risks and adverse information, or, at minimum, to downplay it (the JPMC response to Basel III can be viewed in this light). Look closely at those novel changes, and inspect them closely for concealed risks.
Impossible business requirements: Sometimes an organization needs an outcome so desperately that it can only be achieved by some breakthrough that seems impossible. Similar to novel business processes, this creates an incentive to ensure that the solution exists, even if it doesn’t! Consider VW, which needed an innovation in diesel engine technology which was otherwise unheard of. Much like in a changing business environment, this should be seen as an indicator to dig very deeply into the solution, to understand if the solution truly works as advertised, or creates new hazards for the business.
Planning for perversion of incentives: Almost any structural incentive can become perverse – consider that as a structural hazard of an incentive – but incentives can be instrumented to look for those hazards. A variant of the pre-mortem is very helpful: consider that the incentive will create a perverse incentive, and then try to identify how that happened. Putting in place measurements to detect those outcomes can be helpful (Is this incentive significantly more effective than we anticipated? Is the business generated by this incentive structurally good?).
How much is enough?
Ultimately, the question that risk management programs seek to answer is “How much risk reduction is enough to get us back into our risk appetite?” Or, rephrased, “How do you know that you did the best that you could, given the circumstances?”
The answer to that question isn’t a simple one, but it boils down to an understanding of how comfortable you are with the actions you took, and the decisions you made, given what you could know at the time. Of course, with perfect foresight, you would perfectly navigate the risk environment, and only make bets that are worthwhile. But you don’t have perfect foresight, so don’t apply it in hindsight.
Are you paying attention to risk? Are you willing to look in uncomfortable places for risk? Are you controlling for the risk you incentivize? Are you comfortable with where you’ve drawn the line between the hazards you’re mitigating and the ones you aren’t?
What is Risk?
Risk is anything that has a chance of adversely impacting your business. Risk isn’t intrinsically a bad thing, all entities have a risk appetite that balances the risks they take against the rewards they seek. Companies have to invite risk to pursue rewards; consider that merely making a profit invites competitors who will increase your risk. Risks exist in many broad categories – often, a practitioner in one category thinks of their kind of risk as being the only kind that matters – and it’s important to apply risk management thoughts across the spectrum of risk. The most prevalent risk just comes from liquidity (having enough cash to operate), which can include credit risk (the money you are owed … doesn’t materialize). You might have risk that comes from your market (you need specific truths to operate, like a bear market or zero interest rates), your business strategy (your specific market strategy hinges on an underlying axiom, like people renting movies in a store), or compliance regimes (you can be put out of business simply for not following a rule). You can also face risks from reputation (if people no longer are willing to do business with you) or operations (your security and safety practices).
Within those broad risk areas, we can think of significant amounts of risk as coming from hazards. Hazards are the subset of risks that aren’t intrinsic to your strategy, and have the potential to be surprisingly disruptive.
Hazards come in many flavors. Some are procedural: in execution of your strategy, you might make errors. Some are adversarial or environmental: other entities outside your control could harm you through this hazard. And some are perverse incentives: you might incentive individuals on your team to do very dangerous things in execution of your strategy. Each of these requires different forms of oversight to address, especially in places where they might interact.
Procedural Hazards
Many control regimes – from Sarbanes-Oxley to the NIST CSF to a whole host of ISO frameworks – are designed to help companies manage process risk. Unfortunately, these frameworks, alone, seem to be insufficient to control those risks. Overseeing risk can be challenging, as hundreds of detailed controls across an entire enterprise are potentially relevant, and identifying specific problematic areas isn’t an easy task. Two important questions might help drive towards identifying hazards.
What is the scope of a control system? Perhaps a company has a strong control in Identity and Access Management, and can report flawless execution in ensuring that only appropriate staff get access to systems. But lost in the nuance of reporting is that the relevant control only applies to a subset of the systems in the company. It’s the most important set of systems, of course, but importance is in the perception of management. Right next to those important systems might be other, uncontrolled systems that don’t have good controls, which create hazards for the adjacent controlled systems. Understanding where controls don’t cover the full scope of a company is an important first step.
How effective is the control system? Some control systems look shiny from the outside, but on the inside, don’t actually provide meaningful protections. It’s important to understand if there is a simple measurement that summarizes the control, which is also tied into the protections the control provides. Perhaps the measure is reporting on activity (“We approved 75 products for launch this quarter”) and not on impact (“100% of products had absolutely no reported issues”). An impact measure might reveal implausibility, a failure rate of 0% is not necessarily an indicator of a strong system. It’s more likely an indicator of a control system that has no effect.
Combine these two questions as you consider how to report on the effectiveness of an overall control system. Control effectiveness should report both on scope (what percentage of the system is controlled?) and effectiveness (what is the measure of process effectiveness?). Risk appetite should be used to establish reasonable ranges for both of these measures, to identify when escalation will be needed to course correct, and how much escalation (telling executive management is likely a different threshold than telling the board). Identifying those thresholds before you cross them will save a lot of energetic conversation about whether or not something should be escalated.
Environmental and Adversarial Hazards
Some systems have defects that can go badly wrong if exploited in just the wrong way. Sometimes that exploit needs a malicious actor, a criminal who wants to create harm for your business. Other times that exploit doesn’t require malice; perhaps an extreme winter storm pushes your system outside its design limits.
These hazards are sometimes challenging to talk about. The hazards aren’t always easy to find, and rarely with a simple checklist. Sometimes the hazards are tolerable, you aren’t necessarily happy to have them, but you’ll tolerate them for a time. Sometimes, these hazards are so intertwined into your system design and business process that even if you do decide to reduce the hazard, you’ll need to spend years coordinating cross-functional projects to root it out.
Discovery: One way that many companies identify these hazards is to employ experts who just know where to look. Unfortunately, this approach relies on having a specific kind of unicorn: a deeply technical employee with broad-based knowledge of your entire system, a long memory to track issues, and the communication skills to educate your executive team about the hazards. A more reliable approach is to embed hazard analysis all throughout the design process, and capture the hazards into a registry; and have that registry continuously reviewed – perhaps reassessing a few a month – to keep it updated with known hazards.
Mitigation: Some of those hazards you will need to mitigate. You don’t need to reduce them all to zero (sometimes just taking the edge off by a little bit is sufficient to bring the risk back into your appetite), but once you decide to reduce the impact of the hazard, it’s helpful to identify success criteria. Think of success criteria as a contract with your future self: “if I do this much work, measurable by this outcome, and the world hasn’t changed to make this more dangerous, then I get to celebrate success.” It will be tempting along the way to move the goalposts closer, because mitigation projects can take longer than you originally expected. Inspect that urge. Did you really misestimate the danger originally, or do you just have fatigue and would like to be done, even if the hazard remains uncontrolled?
Awareness: Some of your hazards you aren’t going to mitigate. Perhaps the hazard is too embedded in your way of doing business. Maybe the hazard is just below the level where it would be urgent to fix. This is uncomfortable, because you’ll have to acknowledge the presence of these hazards, and it’s a natural reaction to avoid talking about them. But you must, because the only real way to understand the risk appetite is to actually talk about the hazards that you accept, especially in the context of all of the hazards contained in your registry. Gaining awareness (likely not comfort, but at least awareness) of which risks are accepted make assessing new and novel risks into an easier task.
Incentivized Hazards
The most pernicious hazards an organization faces are those that it creates for itself, by putting its own employees’ incentives at odds with its long-term best outcomes. Sometimes this might be through ill-thought through systemic incentives (consider JPMC’s “London whale” or the Wells Fargo cross-selling debacle); other times it might be created by specific pressures to achieve results (look at Volkswagen’s DieselGate or Theranos).
Most incentivized hazards create a tension between what ought to be the values and cultures of a company (which are often just plaques on a wall, rather than living touchstones), and the short-term needs of a company. Incentives can be novel solutions to a changing business environment, or might arise from impossible business needs. But detecting perverse incentives isn’t impossible; it just requires extra care.
Culture: We shouldn’t expect that employees will be the only line of defense against a hazard, but we should expect that they should feel uncomfortable with conflicting goals – but that they should feel comfortable raising that conflict with management. Organizational values should be viewed like a detour sign: they indicate which paths to avoid. Perhaps, to avoid a Wells Fargo style incident, a value like “Serve the best interests of our customers” would be helpful to create tension against “cross-sell as many products as possible to our existing customers.”
Changing business environment: When the environment alters in a significant fashion, novel solutions to the problem create an automatic perverse incentive: the novel solution absolutely cannot be permitted to fail. The team responsible for the solution is automatically incentivized to hide risks and adverse information, or, at minimum, to downplay it (the JPMC response to Basel III can be viewed in this light). Look closely at those novel changes, and inspect them closely for concealed risks.
Impossible business requirements: Sometimes an organization needs an outcome so desperately that it can only be achieved by some breakthrough that seems impossible. Similar to novel business processes, this creates an incentive to ensure that the solution exists, even if it doesn’t! Consider VW, which needed an innovation in diesel engine technology which was otherwise unheard of. Much like in a changing business environment, this should be seen as an indicator to dig very deeply into the solution, to understand if the solution truly works as advertised, or creates new hazards for the business.
Planning for perversion of incentives: Almost any structural incentive can become perverse – consider that as a structural hazard of an incentive – but incentives can be instrumented to look for those hazards. A variant of the pre-mortem is very helpful: consider that the incentive will create a perverse incentive, and then try to identify how that happened. Putting in place measurements to detect those outcomes can be helpful (Is this incentive significantly more effective than we anticipated? Is the business generated by this incentive structurally good?).
How much is enough?
Ultimately, the question that risk management programs seek to answer is “How much risk reduction is enough to get us back into our risk appetite?” Or, rephrased, “How do you know that you did the best that you could, given the circumstances?”
The answer to that question isn’t a simple one, but it boils down to an understanding of how comfortable you are with the actions you took, and the decisions you made, given what you could know at the time. Of course, with perfect foresight, you would perfectly navigate the risk environment, and only make bets that are worthwhile. But you don’t have perfect foresight, so don’t apply it in hindsight.
Are you paying attention to risk? Are you willing to look in uncomfortable places for risk? Are you controlling for the risk you incentivize? Are you comfortable with where you’ve drawn the line between the hazards you’re mitigating and the ones you aren’t?